Beyond Vibe Coding: Master the Ralph Wigum Loop for Autonomous AI Apps
How to make your vibe coded app work.
The limitations of random prompting ('Vibe Coding')
"Vibe coding"—the act of casually prompting an LLM and hoping for the best—has had its moment in the sun. While vibe coding is excellent for small scripts or quick fixes, it hits a hard ceiling when complexity scales.
The thrill of one-shotting a component fades quickly when you realize you have built a house of cards without a blueprint. Without structure, context windows bloat, hallucinations creep in, and the application becomes unmaintainable. We are reaching the limits of what random prompting can achieve, necessitating a shift toward systems that prioritize planning over probability.
Why you need to remain in the driver's seat
The allure of autonomy often leads developers to abdicate responsibility, letting the agent "figure it out." However, the most effective AI workflows keep the human engineer firmly in the driver's seat, particularly during the planning phase.
Structure does not stifle creativity; it enables it. By defining clear goals and architectural constraints upfront, you transform your role from a gambler to a conductor. The Ralph Wigum loop isn't about letting the AI run wild; it is about creating a harness where the AI's execution is bounded by your strategic intent. This shift from passive observation to active direction is what separates toy demos from production-grade proofs of concept.
Deconstructing the Ralph Wigum Methodology

Philosophy vs. Framework: The true definition
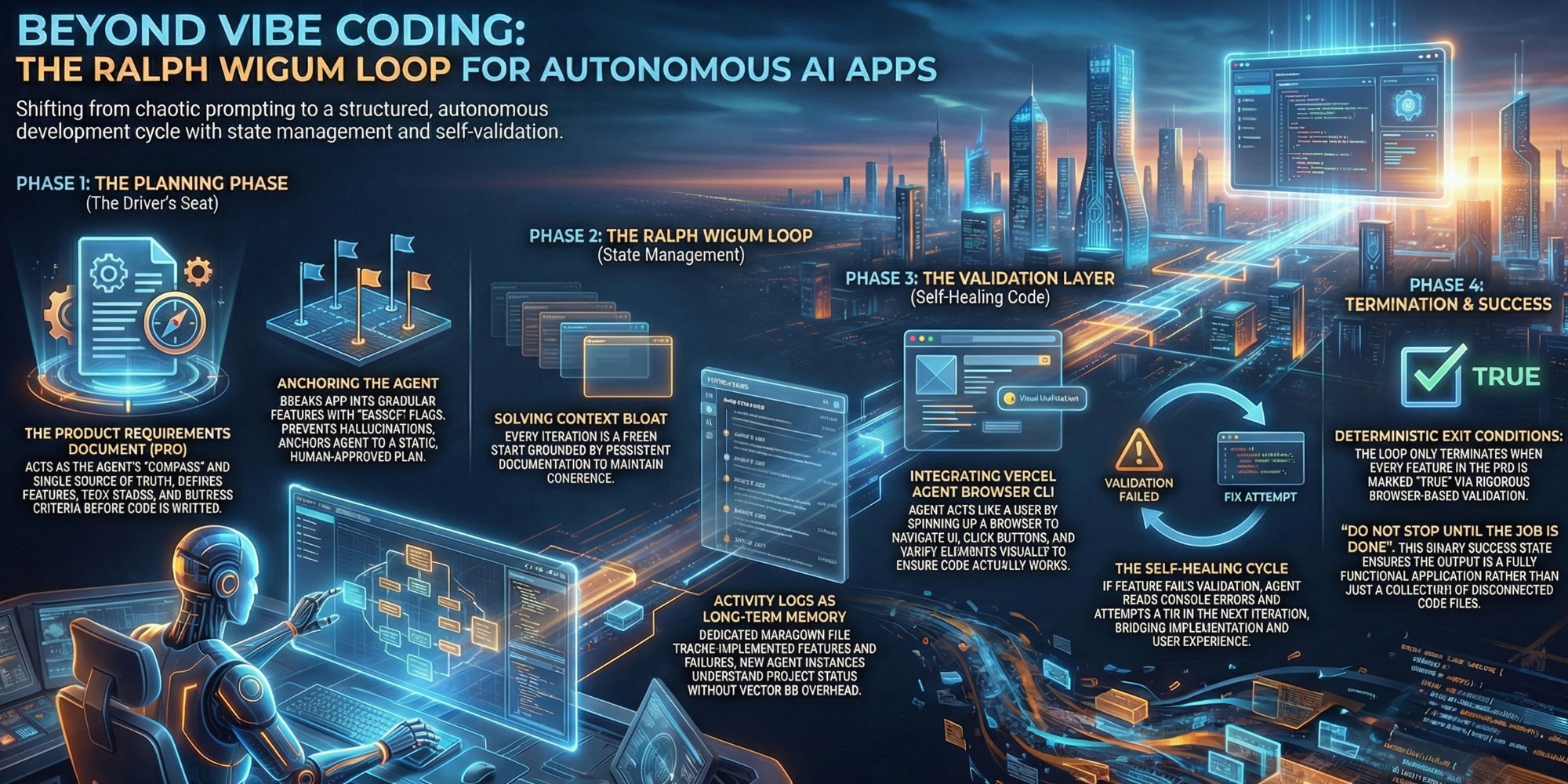
Ralph Wigum is often misunderstood as just another tool or a specific repository. In reality, it is a philosophy of state management for autonomous agents. At its core, it addresses the fundamental challenge of long-running tasks: how to maintain coherence across multiple context windows.
Instead of a single, endlessly growing conversation, the Ralph Wigum philosophy treats every iteration as a fresh start, grounded by persistent documentation. It is a cycle of execution and reflection where the agent reads the current state, attempts a task, validates it, and then updates the state for the next iteration. This "loop" ensures that the agent never gets lost in its own context bloat, maintaining a clear line of sight to the project's original goals.
Moving beyond the official Anthropic plugin
There is an "official" Anthropic plugin for Ralph Wigum, but frankly, it misses the mark. It often fails to reset the context window effectively, which defeats the entire purpose of the methodology. The version we are discussing here is a custom implementation—a lean Bash script that drives Claude Code in a controlled loop.
This custom approach allows for granular control that off-the-shelf plugins lack. By scripting the loop ourselves, we can enforce specific behaviors, like mandatory activity logging and strict validation checks using tools like the Vercel Agent Browser CLI. It is a return to first principles: using simple, robust tools to orchestrate complex AI behaviors rather than relying on opaque "black box" frameworks that hide the logic from you.
Architecting the Loop: Planning for Autonomy

The PRD: Creating a single source of truth
The heartbeat of this entire system is the Product Requirements Document (PRD). In our workflow, the PRD is not a dusty PDF that no one reads; it is the single source of truth that dictates every action the agent takes. Before a single line of code is written, we use a "driver's seat" planning phase to generate this document, defining features, tech stacks, and success criteria.
This file serves as the agent's compass. By breaking down the application into a list of granular features—each with a description, validation steps, and a "passes" boolean flag—we give the agent a deterministic checklist. The agent cannot hallucinate new requirements because it is constantly anchored back to this static, human-approved plan. It transforms abstract goals into executable instructions.
Activity Logs: Giving your agent long-term memory
If the PRD is the compass, the Activity Log is the agent's memory. Since we reset the context window with every loop iteration to save tokens and maintain focus, the agent needs a way to remember what it did ten minutes ago. We solve this with a markdown file specifically for logging progress.
At the end of every loop, the agent must update this log with what was implemented, what worked, and what failed. When the next loop starts, the new agent instance reads this log to understand the project's current status. This simple mechanism provides "long-term memory" without the technical overhead of vector databases or complex retrieval systems. It ensures continuity, preventing the agent from repeating work or getting stuck in loops of failure.
The Validation Layer: Self-Healing Code

Integrating Vercel Agent Browser CLI
Building code is easy; ensuring it works is hard. This is where we integrate the Vercel Agent Browser CLI. We don't just want the agent to write a unit test; we want it to act like a user. This tool allows the agent to spin up a browser instance, navigate to the localhost URL, click buttons, fill forms, and verify UI elements visually.
This capability transforms the loop from a coding engine into a QA engine. When the agent implements a feature, it immediately spins up the browser to verify it. If the button doesn't work, it sees the failure, reads the console errors, and attempts a fix in the next iteration. It is self-healing code in the truest sense, bridging the gap between implementation and user experience.
Exit conditions: Ensuring features pass before proceeding
The most critical component of the Ralph Wigum loop is the exit condition. Without strict boundaries, an autonomous agent could burn through your API credits indefinitely. We define a simple but rigorous rule: the loop only terminates when every single feature in the PRD has its `passes` flag set to `true`.
This boolean flag is the gatekeeper. The agent is only allowed to mark a feature as "passing" after it has successfully validated it using the browser tools. This creates a binary success state for the entire project. We essentially tell the system, "Do not stop until the job is done." It aligns the agent's incentives with the developer's goal: a fully functional, validated application, not just a folder full of code files.
Conclusion
The Ralph Wigum Loop represents a maturity milestone in the evolution of AI-assisted engineering. By moving beyond the slot-machine appeal of "vibe coding" and embracing a structured, self-validating architecture, developers can now build substantial proofs of concept with unprecedented speed.
The real power here isn't just in the code generation; it is in the validation. Whether you are validating a new tech stack like Neon and Clerk, or testing a complex architectural thesis, this loop allows you to fail fast and succeed faster. We are no longer just prompting; we are orchestrating. It is time to get back in the driver's seat and start building with intent.
References:
Stay in the loop
Get notified when I publish new articles and projects.


